[CS231n 2016] 9강 Understanding and Visualizing Convolutional Neural Networks

1. Visualize patches that maximally activate neurons

각 행은 pool5에서 추출한 임의의 neuron이 가장 activate 시키는 부분을 보여준다.
2. Visualize the filters/kernels(raw weights)
이미지에 직접 작용하는 필터는 conv1에 있는 필터이므로, 이것만 해석 가능하다.
다음의 layer 들의 weight들은 시각화할 수 있지만 low image에 대한 것이 아닌 layer1의 activation에 대한 시각화이기 때문에 큰 의미가 있지는 않다.


3. Visualize the representation
classify 하기 직전의 fc7 layer에서 추출한 representation으로 시각화하는 방법이 있다.

대표적인 방법으로 t-sne 시각화 방법이 있다. cnn의 시각으로 볼 때 유사하는 것을 가깝게 위치시켜 준다.

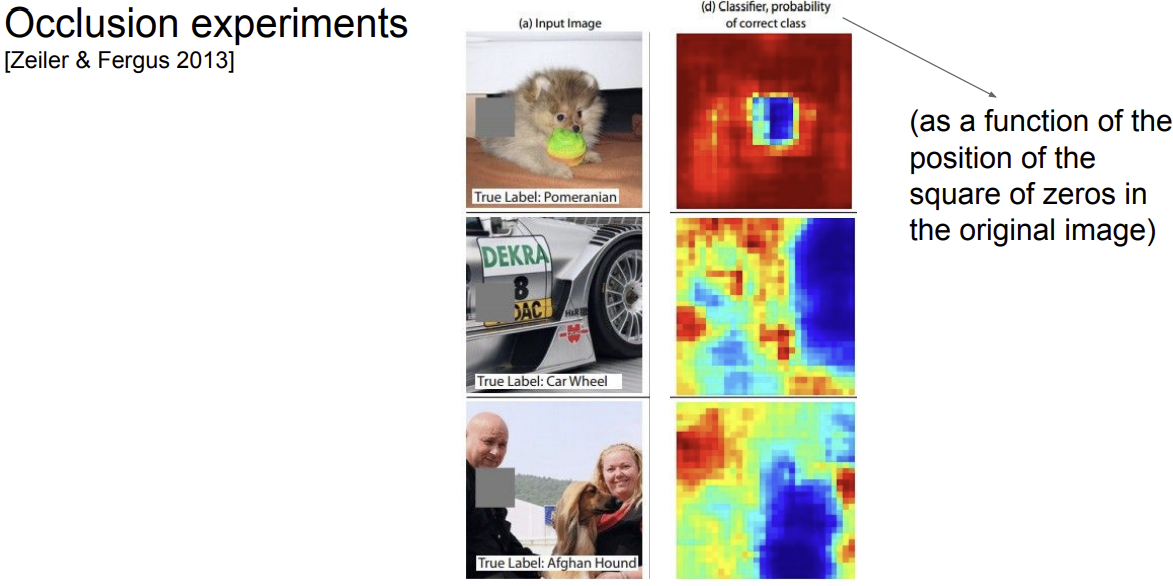
4. Occlusion experiments
occlusder를 슬라이딩 시켜 어느 부분에 위치해 있을 때 정확하게 classify 하는 확률이 변하는지 확인
5. Visualizing Activations

1. Deconvolution-based approach
Q: how can we compute the gradient of any arbitrary neuron in the network w.r.t. the image?
임의의 뉴런이 있는 곳까지 forward pass를 해주고, activation을 구한다.
그 후 해당 layer의 뉴런의 gradient를 1, 그 외에는 gradient를 0로 둔 뒤 back propagation을 수행한다.

Guidied backpropagation을 사용하면 positve한 influence한 반영하게 되어 선명한 이미지를 얻을 수 있다.
relu 대신 modifed relu를 사용하면 Guidied backpropagation을 사용할 수 있다.
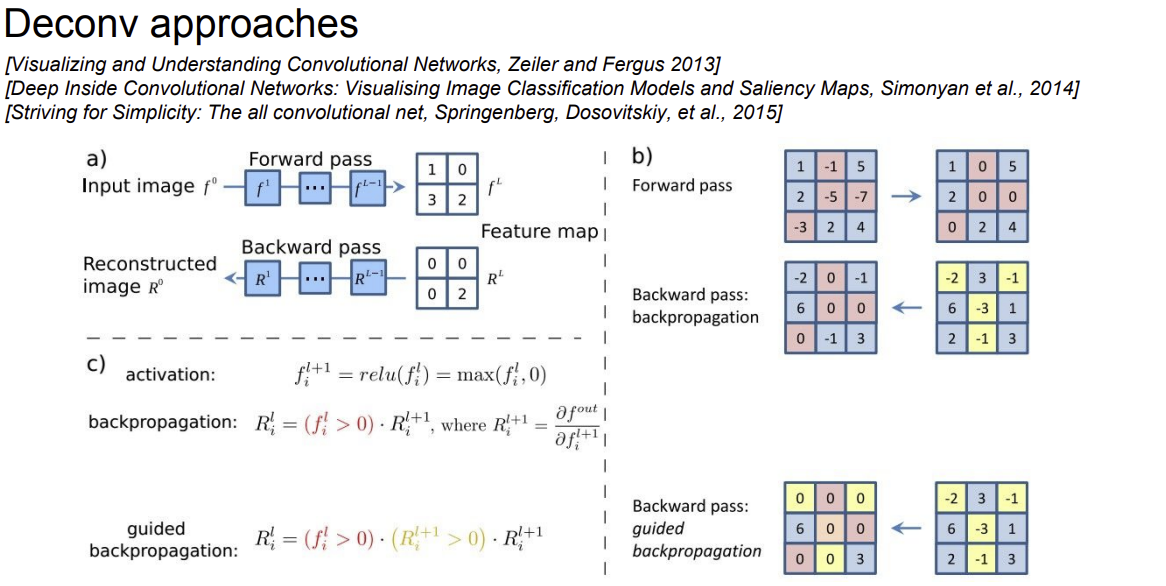
backward deconvnet은 relu의 영향을 받지 않아, -인 값들은 0으로 처리 된다.

2. Optimizationi-based approach
이미지를 파라미터로 이용하는 방법, weight의 update X


1. Find images that maximize some class score

2. Visualize the Data gradient

이런 방법을 사용해 segmentation을 수행하는 grabcut이라는 알고리즘도 있다.
임의의 뉴런에 적용해보면 다음과 같은 과정을 수행할 수 있다.


Question: Given a CNN code, is it possible to reconstruct the original image?
FC 7 layer의 code로 이미지를 복원할 수 있을까?
Find an image such that:
- Its code is similar to a given code
- It “looks natural” (image prior regularization)

사실 FC 7 layer만이 아니라 다른 layer에서도 복원이 가능하다.
ex) 구글의 deep dream도 image에 대한 optimization 기법을 사용한다.
gradient를 activation 값으로 사용하게 되어 relu에서 boost 효과가 일어나 여러가지 그림을 합성한 듯한 이미지가 나타나게 됨
ex) NeuralStyle

1. content 이미지를 convnet에 넣고, 각각의 layer에서 low activation을 저장한다.
2. Style 이미지를 넣고, style gram matrices를 얻는다.
3. Optimize over image to have
- The content of the content image (activations match content)
- The style of the style image (Gram matrices of activations match style)
Question: Can we use this to “fool” ConvNets??(속이다)
=> Adversial Attack



0.5씩 조정하여 적대적인 X를 만들 수 있다. class 0에 해당하는 이미지를 class 1로 분류하게 만들 수 있다.
이는 linear classifier의 본질적인 문제이다.
“primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature“
(and very high-dimensional, sparsely-populated input spaces)
Backpropping to the image is powerful. It can be used for:
- Understanding (e.g. visualize optimal stimuli for arbitrary neurons)
- Segmenting objects in the image (kind of)
- Inverting codes and introducing privacy concerns
- Fun (NeuralStyle/DeepDream)
- Confusion and chaos (Adversarial examples)