
TODO
- parameter update schemes
- Learning rate schedules
- Dropout
- Gradient checking
- Model ensembles
Parameter update
Stochastic Gradient Descent(sgd)

현재는 단순한 gradient descent 방법을 사용하고 있지만, 앞으로 복잡한 방법에 대해 설명할 예정
단순한 Stochastic Gradient Descent(sgd)는 느리다.
sgd => mini-batch(일부 데이터의 모음)로 loss function을 계산
왜 이렇게 sgd는 느릴까??
수직으로는 경사가 가파르고 수평으로 완만한 loss function을 생각해보자.

Q: What is the trajectory along which we converge towards the minimum with SGD?
수직으로는 빠르게 수평으로는 느리게 이동하여 다음과 같이 이동하게 될 것 이다.

그래서 sgd가 느리게 이동하게 되는 것이다.
Momentum update
x를 직접 업데이트 하는 것이 아닌, v(속도)를 업데이트 하여 v를 통해 x를 업데이트 해준다.
(언덕에서 공을 굴리는 느낌)

처음에는 overshooting이 발생하지만 결국에는 minimum에 빠르게 도달하게 된다.
Nesterov Momentum update
NAG(Nesterov Accelerated Gradient)라고도 함. momentum보다 항상 covergence rate가 좋다.
일반적으로 momentum은 2개의 part로 나누어져있다.
mu*v(momentum step) - learningrate*dx(gradient step)

gradient step을 계산하기 전에 momentum step을 계산하고 그 종료점에 gradient step을 구해준다.

하지만, 불편한 부분이 있다.

세타와 다른 위치에서의 gradient를 구하는 것이 일반적인 다른 코드들과의 호환성 측면에서 떨어지게 된다.
그래서 phi를 도입하여 치환하여 위와 같은 식을 구할 수 있게 된다.
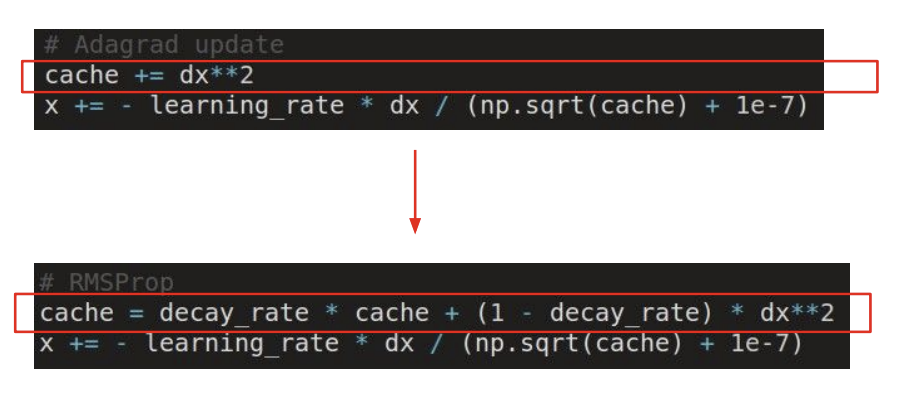
AdaGrad update
cache라는 개념을 도입하게 된다. cache는 building up이 되는 양수

per-parameter adaptive learning rate method라고 한다.
파라미터들이 다른 값의 lr을 가지게 되는 방법
=> 위의 예시에서 AdaGrad를 사용하게 되면, 수직으로는 gradient가 커서 cache가 커지게 되고 lr이 작아지게 되고, 수평으로는 결과적으로 lr이 커지게 된다.
=> 하지만 시간이 흐름에 따라 lr이 0에 가까워지게 되고 학습이 종료되게 된다.(단점)
이를 보완한 것이 바로 RMSProp이다.
RMSProp update
decay rate(parameter)를 도입해 cache의 값을 서서히 올라가게 함.
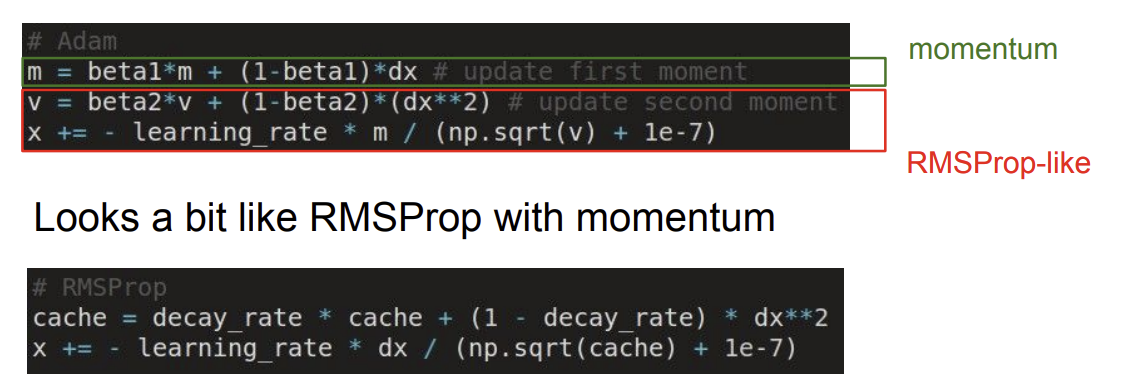
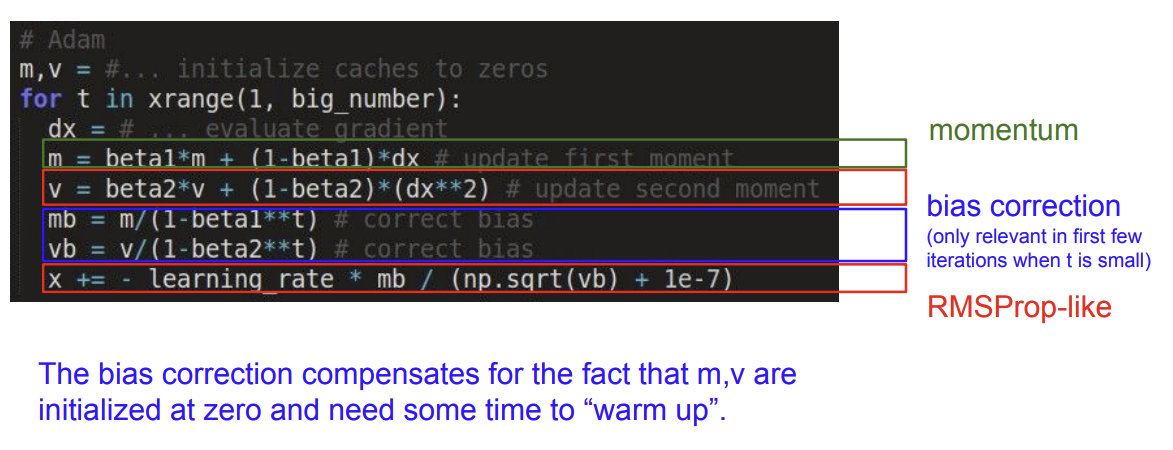
Adam update
momentum과 RMSProp을 결합한 형태
그럼 어떤 learning rate를 사용해야 할까?
=> 초기에는 크게 후에는 줄여서 사용해야한다.

지금까지 배운 update 방법은 1st order optimization method 이다.
=> loss function을 구하는데 있어 gradient 정보만을 사용하는 방법
Secone order optimization methods
Hessian을 통해 경사뿐만아니라 곡면의 구성을 알 수 있어, 바로 최저점으로 갈 수 있게 된다.
그렇다면 learning rate도 필요가 없게 된다.

장점 : learning rate가 필요가 없게 된다. convergence rate가 빠르다
단점 : 사실 neural net에서는 현실적이지 못하다. 엄청 큰 행렬을 역행렬 연산을 해야하기 때문에..
하지만 다른 방법으로 시도해보자는 시도가 있음.
ex) BGFS, L-BFGS


그래서 결론은,
보통 adam을 사용하는 것이 좋고, full batch update를 할 수 있는 환경이라면 L-BFGS를 사용해보자.
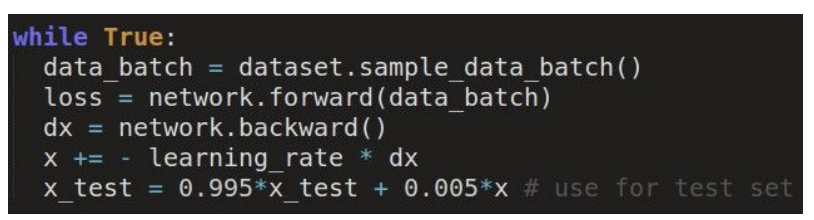
Evaluation : Model Ensembles
1. Train multiple independent models
2. At test time average their results
=> Enjoy 2% extra performance
=> 단점: 여러개의 모델 관리 이슈, test 속도가 느려짐.
여러개의 모델이 아리나 단일 모델에서 checkpoint 간의 앙상블을 하더라도 성능향상을 보일 수 있다.
parameter vector들 간의 앙상블도 성능 향상을 보인다.
Regularization (dropout)
일부 뉴런(노드)를 0으로 랜덤으로 설정해줌
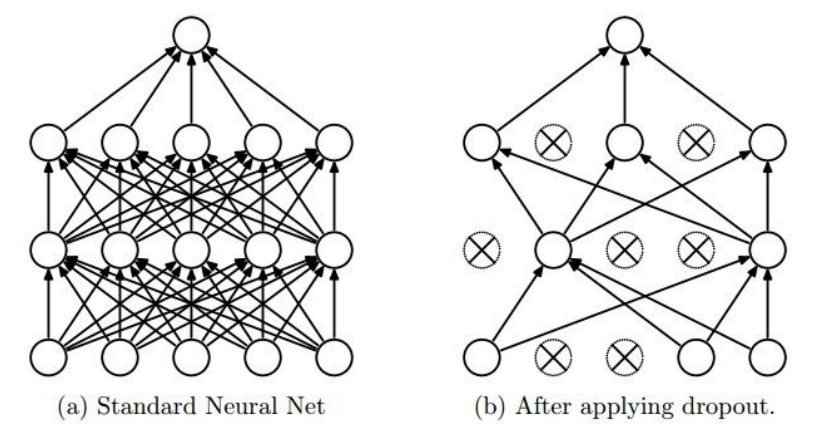
어떻게 좋은 아이디어일 수 있을까?
-> redundant(중복)을 하게 된다.
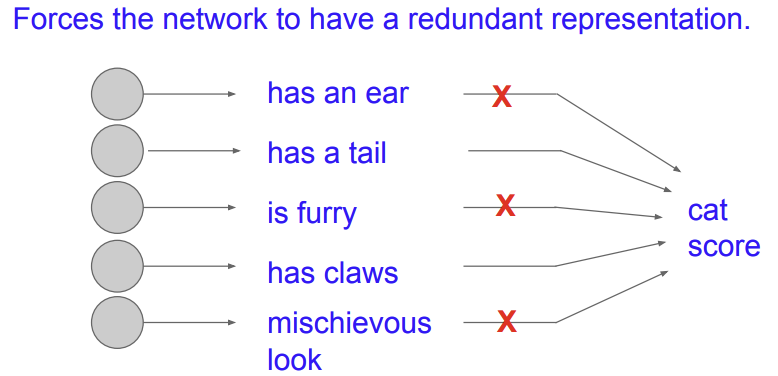
다른 해석으로는 Droppit도 하나의 큰 ensemble로 보게 된다는 것이다.
test time은 어떻게 하게 될까?
-> 모든 뉴런을 turn on(no dropout)으로 test한다.

p=0.5로 할 때 activation이 inflate되게 된다. 따라서 scaling이 필요하다.

이를 편리하게 하기 위해 inverted dropout을 사용해 먼저 /p를 해주는 것이 일반적인 방법이다.

Convolutional Neural Network
본격적으로 활용.. LeNet
history...
Hubel & Wiesel,,, 방향
Topographical mapping in the cortex,,, locality
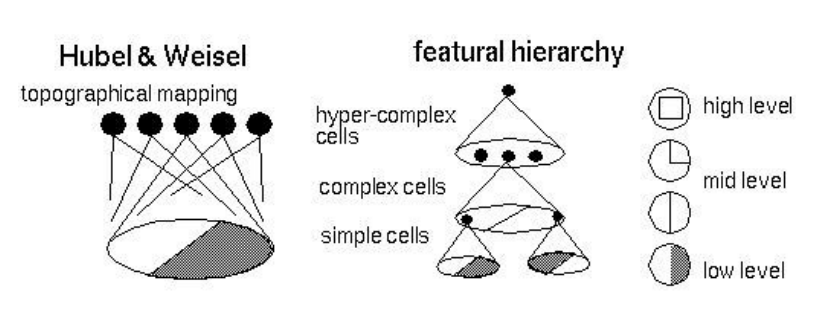
이를 컴퓨터를 활용해 인위적으로 시뮬레이션 해보자!..
Neurocognitron[Fukuchima 1980]
Gradient-based learning applied to document recognition [LeCun, Bottou, Bengio, Haffner 1998]
-> LeNet
ConvNet의 비약적인 발전
ImageNet Classification with Deep Convolutional Neural Networks [Krizhevsky, Sutskever, Hinton, 2012]
-> AlexNet
'컴퓨터비전' 카테고리의 다른 글
| [CS231n 2016] 8강 Spatial Localization and Detection (0) | 2022.07.14 |
|---|---|
| [CS231n 2016] 7강 Convolutional Neural Network (0) | 2022.07.11 |
| [CS231n 2016] 5강 Training NN part 1 (0) | 2022.07.04 |
| [CS231n 2016] 4강 Backpropagation and NN part 1 (0) | 2022.07.01 |
| [CS231n 2016] 3강 Loss fn, optimization (0) | 2022.06.30 |