
컴퓨터 비전의 주요 TASK

Classification + Localization
Classification
Input : image => Output : class label
평가지표 : Accuracy
Localization
Input : image => Output : box in the image
평가지표 : Intersection over Union
Idea #1 : Localization as Regression

Step 1 : Train (or download) a classification model (AlexNet, VGG, GoogLeNet)
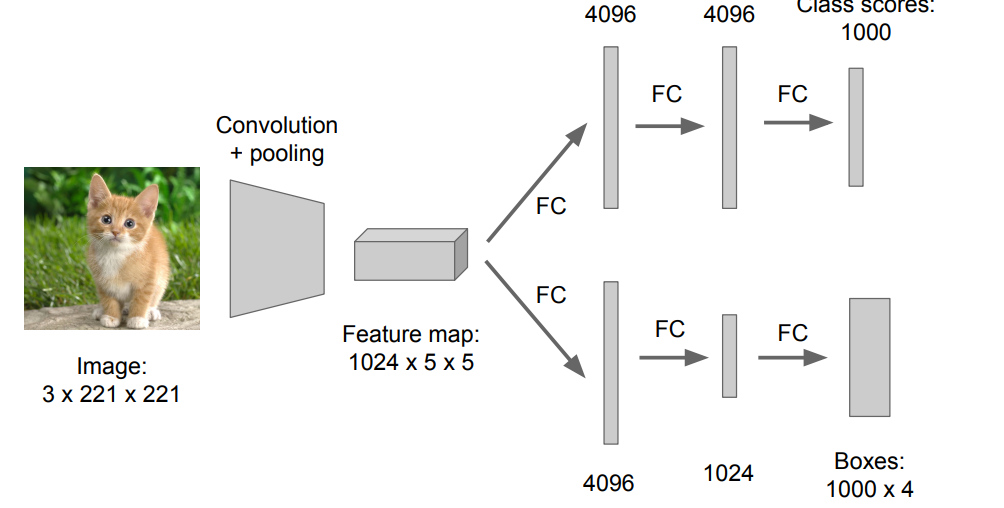
Step 2 : Attach new fully-connected “regression head” to the network
Step 3 : Train the regression head only with SGD and L2 loss
Step 4 : At test time use both heads
Per-class(클래스에 특화된) vs class agnostic regression(클래스에 범용적인)
Class specific: C x 4 numbers (one box per class)
Class agnostic: 4 numbers (one box)
어디에 regression head를 붙여야 될까?
=> After conv layers, After last FC layer

Aside : Localizing multiple objects
정해진 수 K가 있다면 detection을 사용하지 않고 regression만으로도 localization이 가능하다.
Aside : Human Pose Estimation
사람의 관절의 수를 정해져 있기 때문에 regression 만으로도 쉽게 localization이 가능하다.
Localization as Regression
- 매우 간단하다.
- 나름 강력하다.
Idea #2 : Sliding Window
- Run classification + regression network at multiple locations on a highresolution image
- Convert fully-connected layers into convolutional layers for efficient computation
- Combine classifier and regressor predictions across all scales for final prediction
대표적인 예시 : Overfeat
- Winner of ILSVRC 2013 localization challenge

window를 슬라이딩 시켜 regression head에서 bounding box 4개, classification head에서 score 4개를 다음과 같이 만들어 낸다.


위 bbox들을 merge하고, 최종 score도 산출해 낸다.

실제로도 4개보다 훨씬 많은 sliding window를 사용한다.
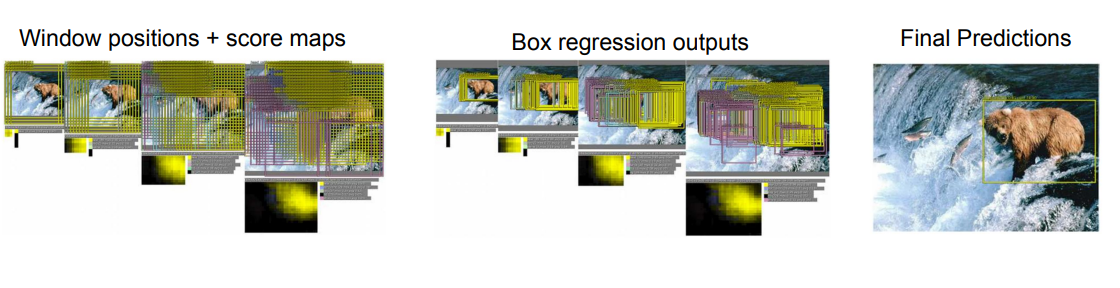
이렇게 되면 연산 자체가 heavy해져 효율적이지 못하다.
따라서 fc layer를 conv layer로 바꿔 주었다.
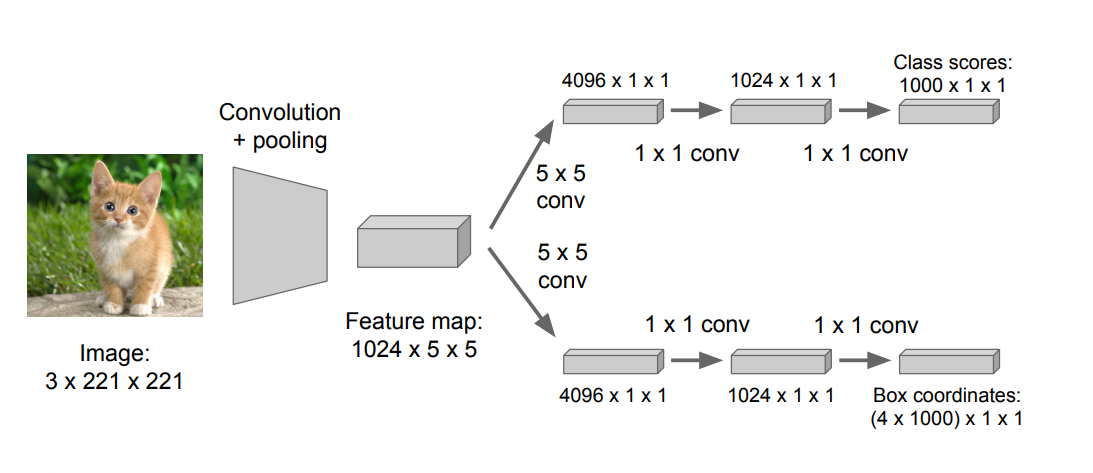
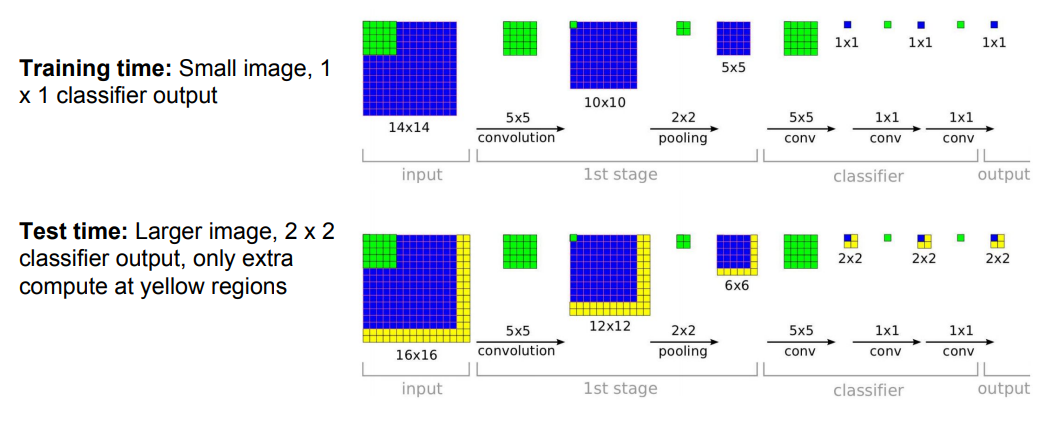
ImageNet Classification+Localization
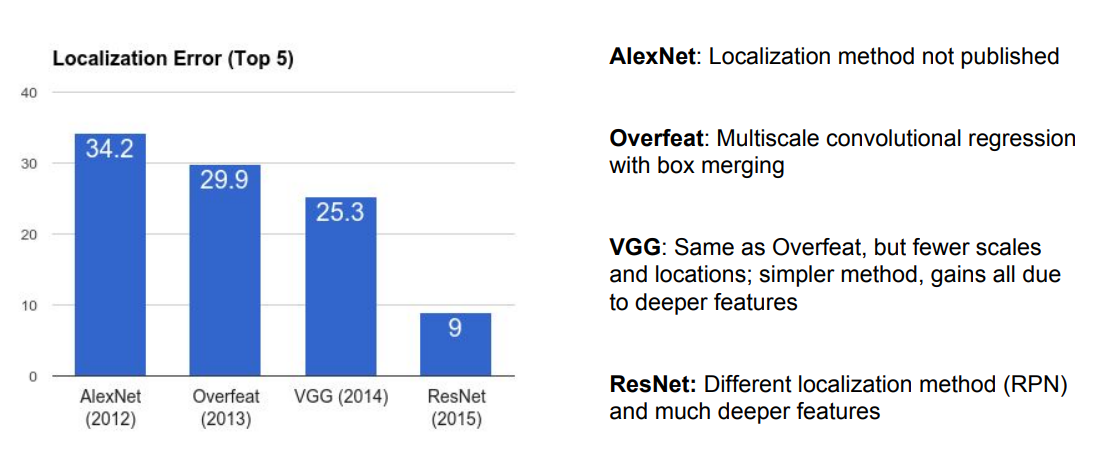
ResNet은 완전히 다른 방법인 RPN(Regional Proposal Network)를 사용해 엄청난 성능 향상을 이뤄냄.
Object Detection
Detection as Regression?
- 이미지에 따라서 object의 개수가 달라져 output의 개수도 달라지기 때문에 regression이 적당하지 않다.
- but,,, YOLO(You Only Look Once)에서는 regression을 사용하긴 한다.
Detection as Classification
box 영역을 보고 classification을 진행하여 detection을 하는 방법
Problem: Need to test many positions and scales
(다양한 사이즈의 많은 window를 필요로 하게 됨.)
Solution: If your classifier is fast enough, just do it
(무거운 classifier만 아니라면, 그냥 해라..)
Problem: Need to test many positions and scales, and use a computationally demanding classifier (CNN)
(무거운 연산인 CNN을 필요로 하는 경우)
Solution: Only look at a tiny subset of possible positions
(의심되는 지역만 보자... Region Proposals)
ex) HOG, DPM
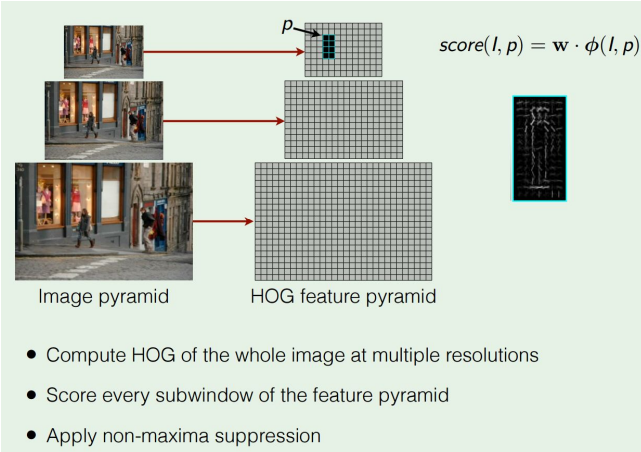
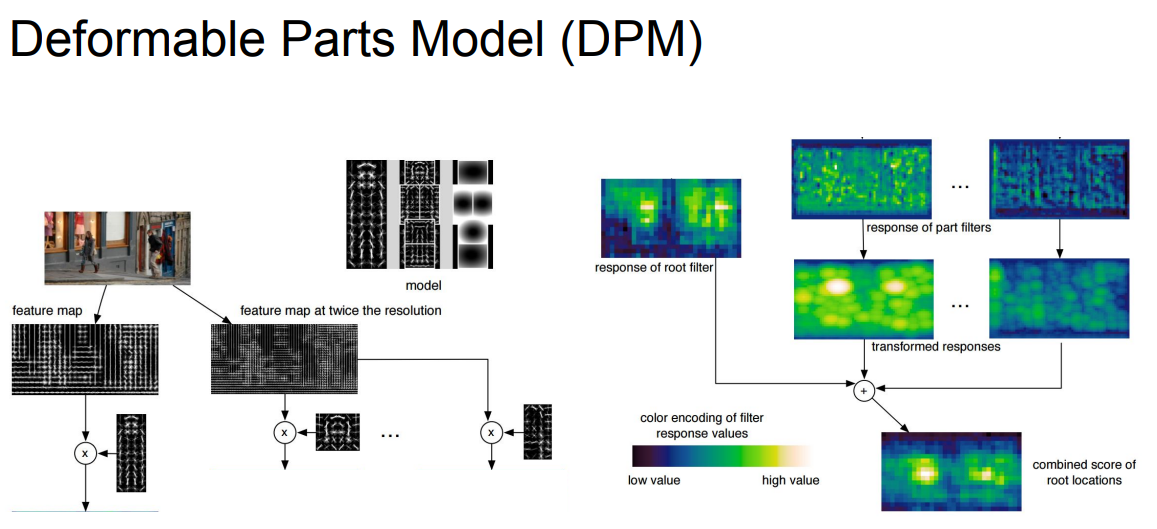
Region Proposals
정확도, 클래스에 상관하지 않고 그냥 blobby한 영역을 매우 빠르게 잡아내는 것
- Find “blobby” image regions that are likely to contain objects
- “Class-agnostic” object detector
- Look for “blob-like” regions

대표적인 방법으로는 Selective Search가 있다.
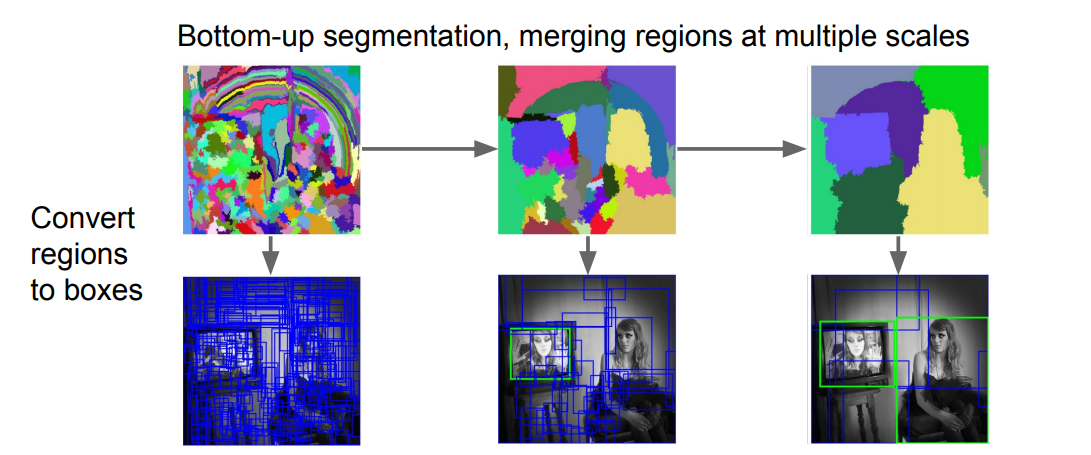
그 외에도 많은 방법들이 있다. (Edgeboxes를 추천해주심)
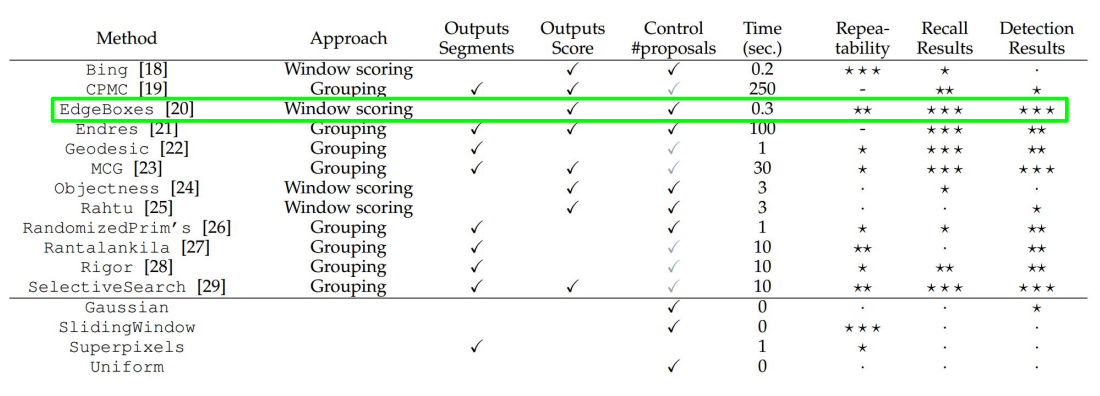
그래서 이런 Region Proposal과 CNN를 결합하여 사용한 것이 바로 R-CNN이다.
R-CNN
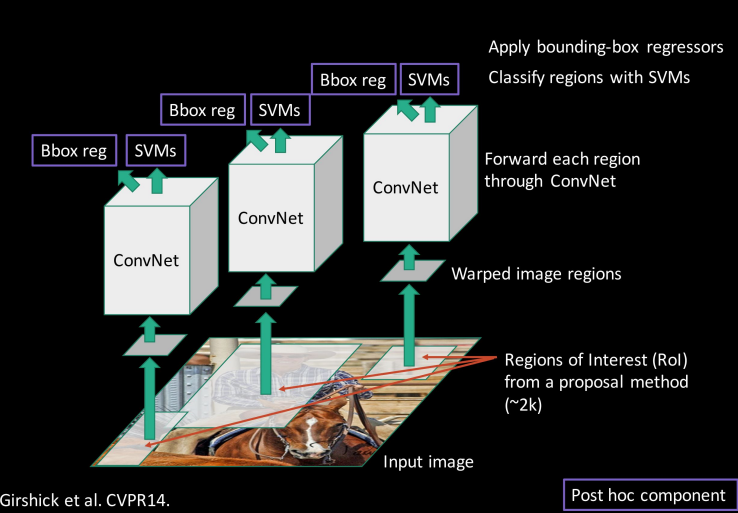
input 이미지를 받아 proposal method를 사용하여 ROI를 뽑아낸다.(약 2000개)
각각의 ROI는 다른 위치와 크기를 가지게 됨.
정사각형으로 warp을 시킴
Conv에 들어가게 됨.
그 후 regression과 SVM을 이용한 classify를 진행시킴.
Step 1: Train (or download) a classification model for ImageNet (AlexNet)
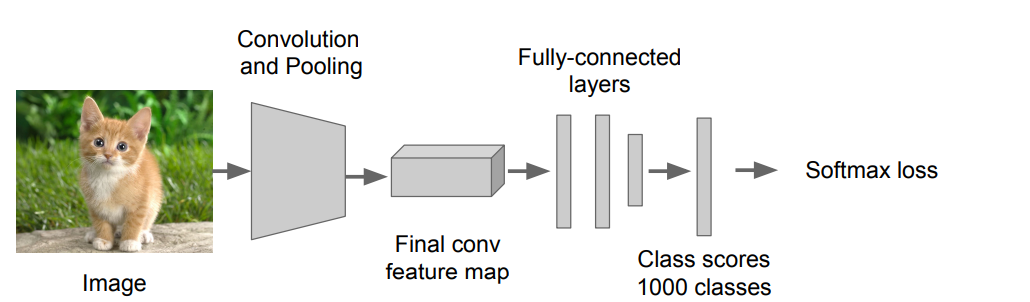
Step 2: Fine-tune model for detection
- Instead of 1000 ImageNet classes, want 20 object classes + background (21개의 class로 바꿔줘야함.)
- Throw away final fully-connected layer, reinitialize from scratch
- Keep training model using positive / negative regions from detection images
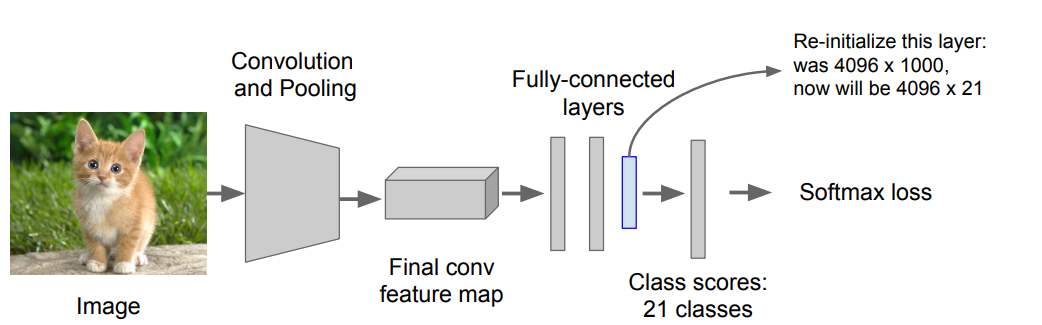
Step 3: Extract features
- Extract region proposals for all images
- For each region: warp to CNN input size, run forward through CNN, save pool5 features to disk
- Have a big hard drive: features are ~200GB for PASCAL dataset!
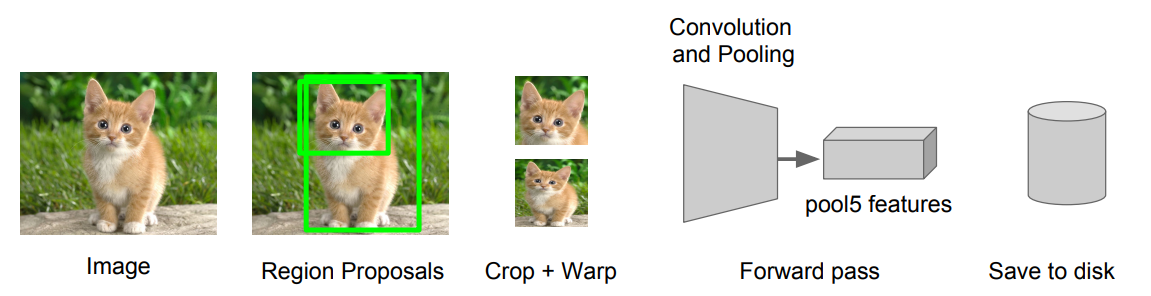
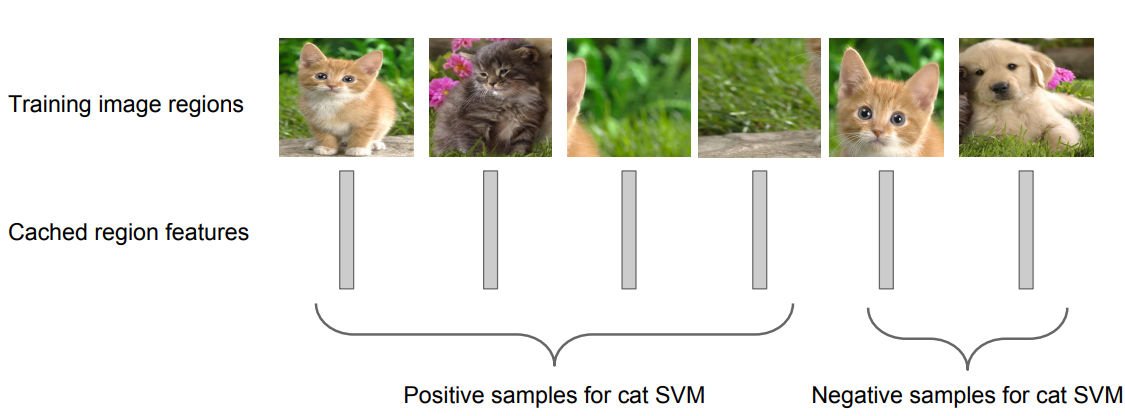
Step 4: Train one binary SVM per class to classify region features
ex) 고양이라면, 고양이인지? 아닌지? 2개 중 하나로 positive, netgative 분류를 함.
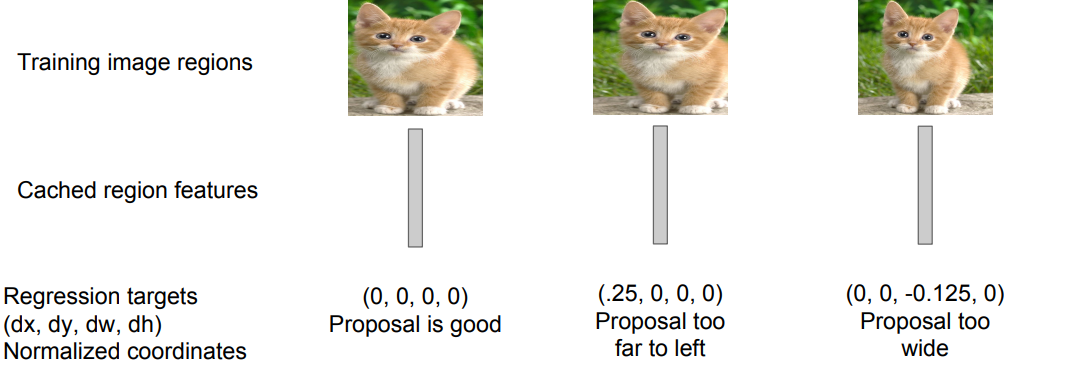
Step 5 (bbox regression): For each class, train a linear regression model to map from cached features to offsets to GT boxes to make up for “slightly wrong” proposals
(region proposal이 항상 정확한 것은 아니기 때문에, cache 해놓은 feature에서 regression을 이용해 정확도를 높혀주는 작업이다. 이는 mAP를 3~4% 정도 높혀준다.
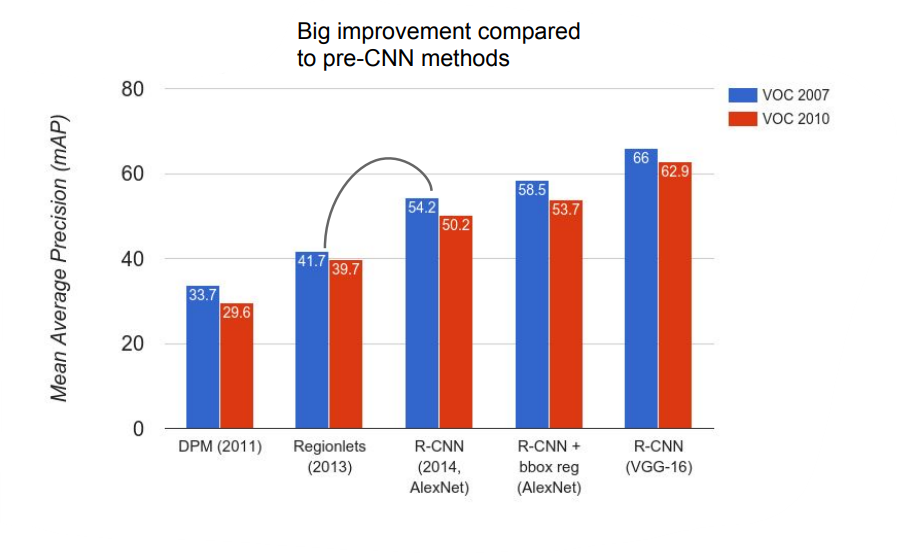
Object Detection : Datasets
PASCAL VOC, ImageNet Detection, MS-COCO...
Object Detection : Evaluation
mean average precision (mAP)
R-CNN의 문제점
1. Slow at test-time: need to run full forward pass of CNN for each region proposal
2. SVMs and regressors are post-hoc: CNN features not updated in response to SVMs and regressors
3. Complex multistage training pipeline
Fast R-CNN
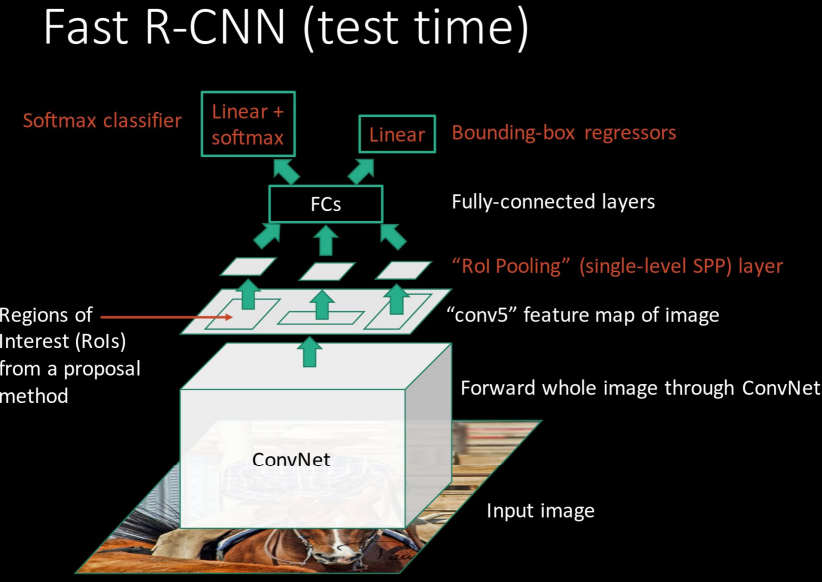
CNN과 region proposal 추출의 순서를 바꾼 것
이미지를 우선 CNN에 돌려 고해상도의 conv feature map을 생성한다.
여기서 proposal method를 사용해 ROI를 추출하고, 이를 ROI Pooling이라는 기법을 사용해
FC layer로 넘겨줘 classifier와 regression을 수행한다.
R-CNN Problem #1: Slow at test-time due to independent forward passes of the CNN
Solution: Share computation of convolutional layers between proposals for an image
R-CNN Problem #2: Post-hoc training: CNN not updated in response to final classifiers and regressors
R-CNN Problem #3: Complex training pipeline
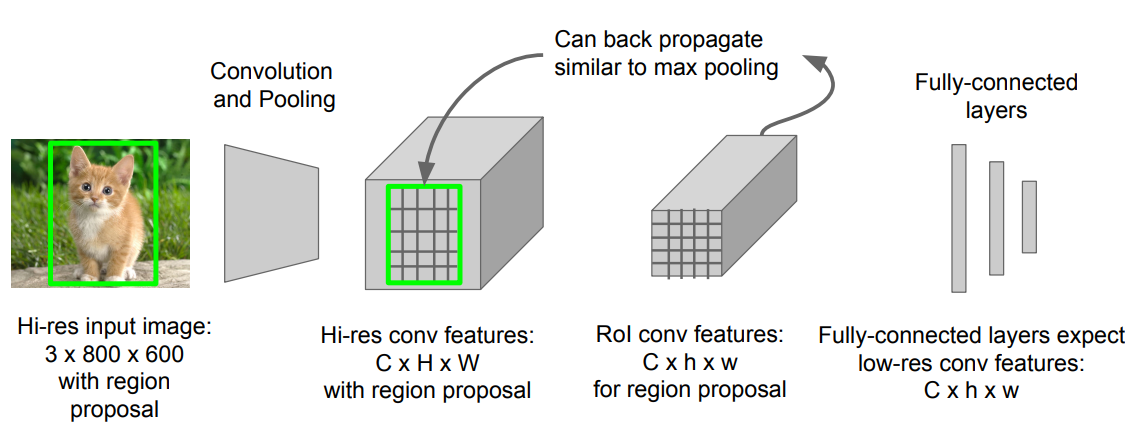
Solution: Just train the whole system end-to-end all at once!
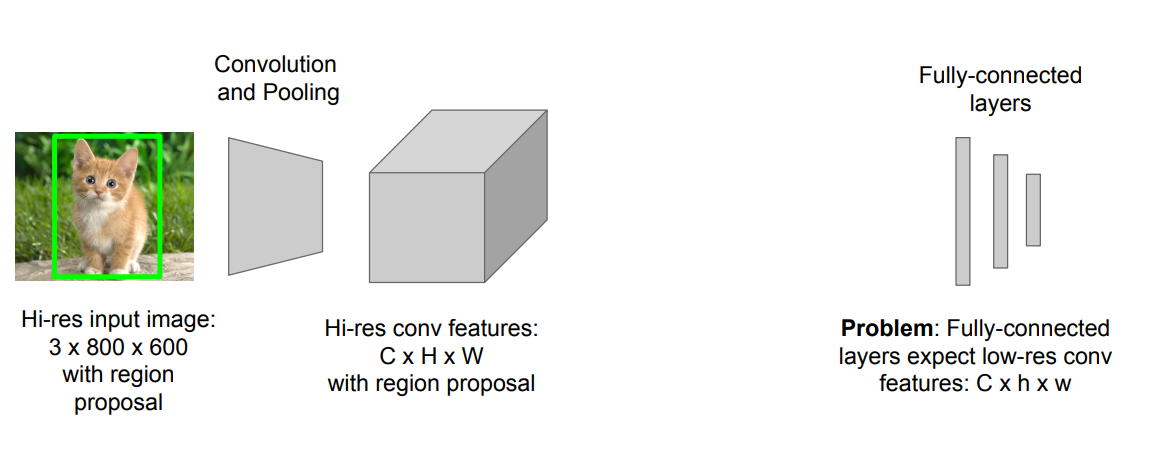
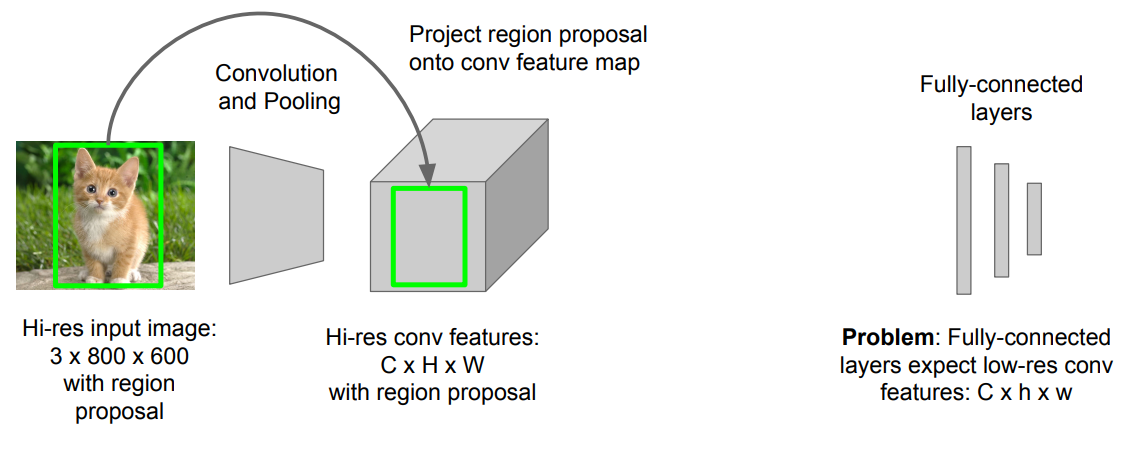
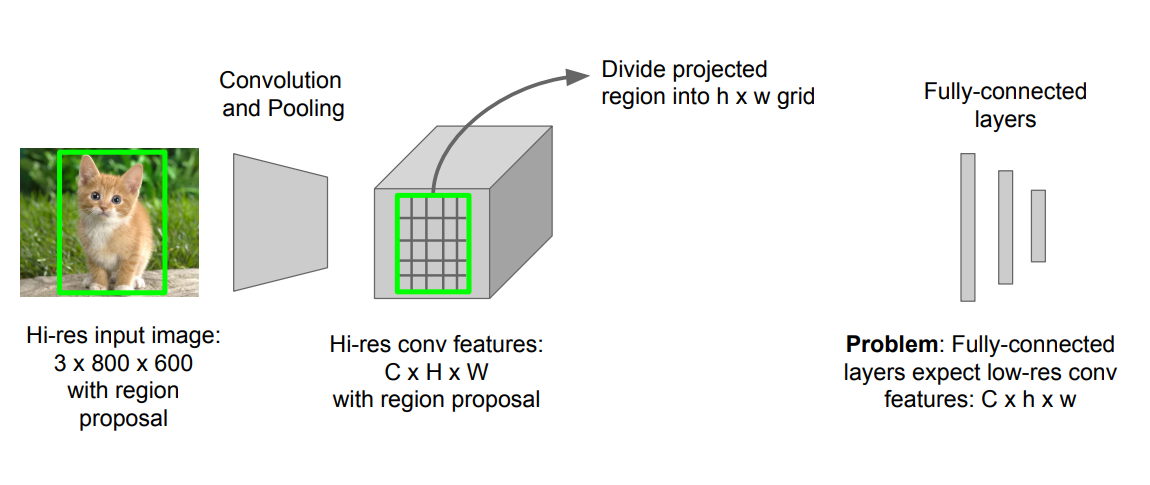
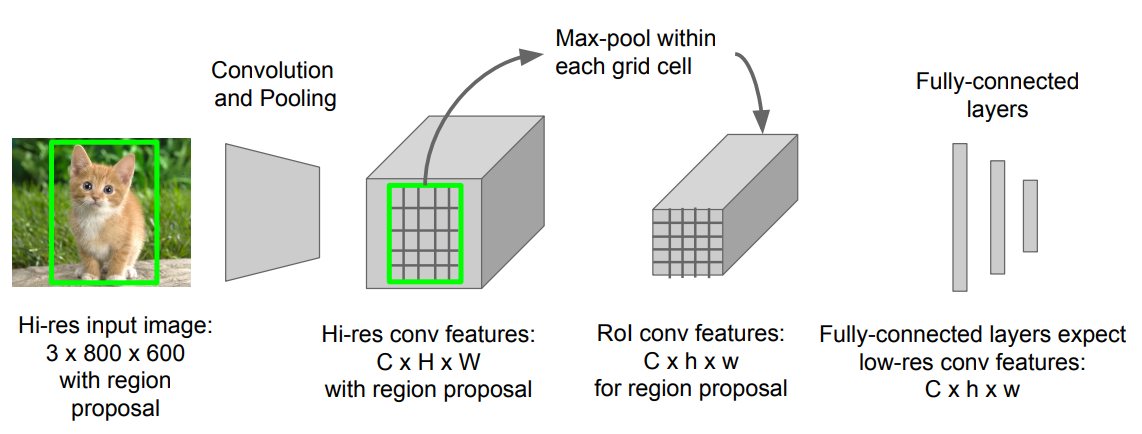
high-res conv feature = > low-res conv feature로 바꿔주는 것을 ROI Pooling이 해결해주게 됨.
ROI Pooling의 과정
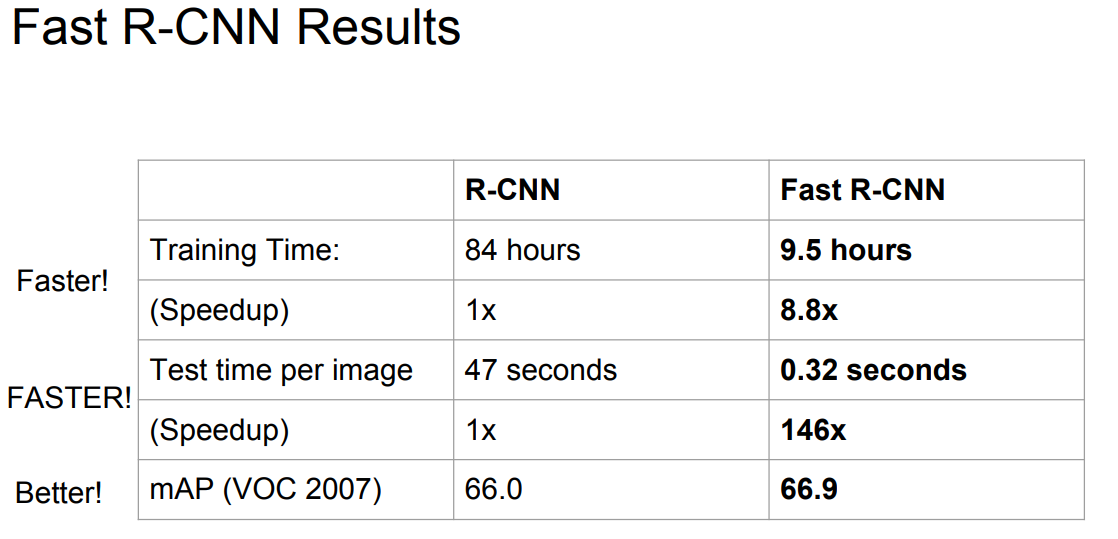
Fast R-CNN 결과
R-CNN은 각각의 Region proposal에 대해 별개로 forward pass
Fast R-CNN은 Region proposal간의 conv layer의 computation을 share하기 때문에 빠르게 된다.
Fast R-CNN의 Problem
region proposal을 포함하게 되면 2초나 걸려 real-time으로는 사용하기 힘듬.

Fast R-CNN의 Solution:
Just make the CNN do region proposals too!
Faster R-CNN
이전까지는 Region Proposal을 외부에서 진행해왔음.
Region Proposal Network를 삽입하여 내부에서 Region Proposal을 수행하게 함.
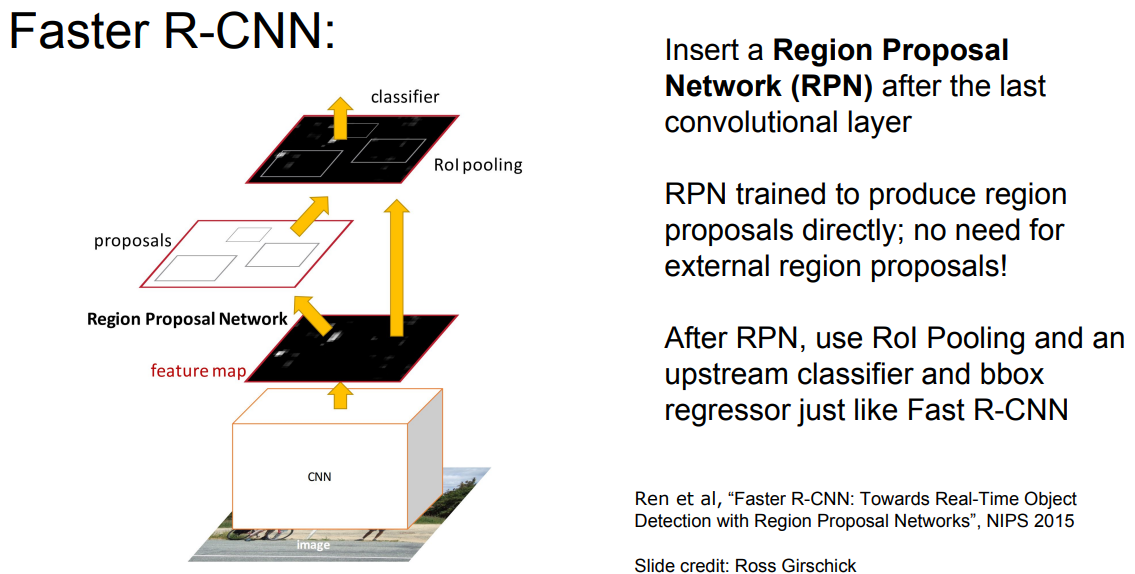
Faster R-CNN : Region Proposal Network
기본적으로 Convolution Net이다. sliding 3x3 window로 Region Proposal을 생성해냄.
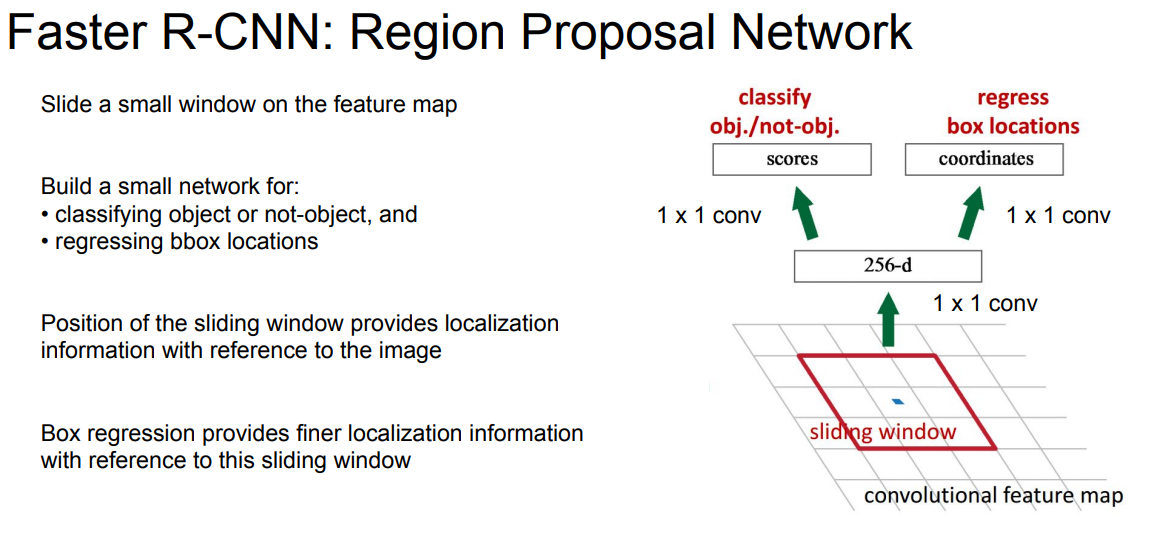
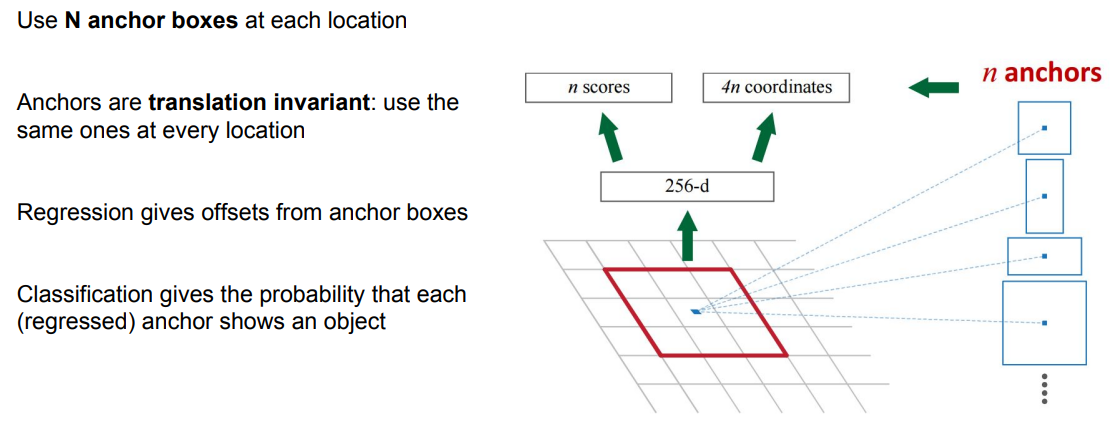
Faster R-CNN : Training

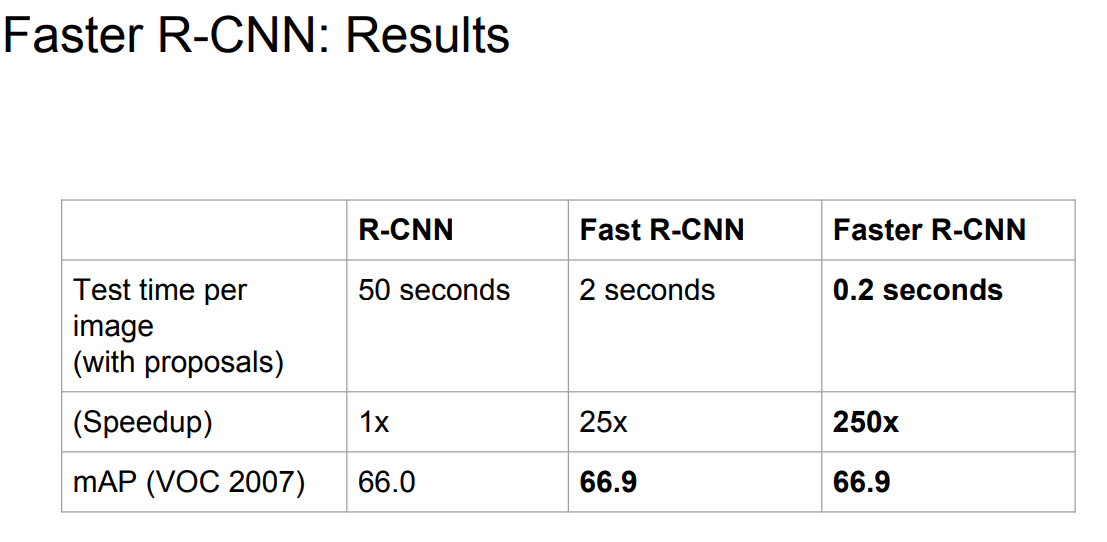
Faster R-CNN : Results
YOLO: You Only Look Once Detection as Regression
Detection을 Regression으로 간주하고 적용하는 기법 이전에는 Detection을 classification으로 간주했었음.
Divide image into S x S grid Within each grid cell(일반적으로 7x7)
predict: B Boxes: 4 coordinates + confidence Class scores: C numbers
Regression from image to 7 x 7 x (5 * B + C) tensor
Direct prediction using a CNN
Faster R-CNN 보다 빠르지만, 성능이 좋지는 않다.
Recap Localization:
- Find a fixed number of objects (one or many)
- L2 regression from CNN features to box coordinates
- Much simpler than detection; consider it for your projects!
- Overfeat: Regression + efficient sliding window with FC -> conv conversion
- Deeper networks do better
Object Detection:
- Find a variable number of objects by classifying image regions
- Before CNNs: dense multiscale sliding window (HoG, DPM)
- Avoid dense sliding window with region proposals
- R-CNN: Selective Search + CNN classification / regression
- Fast R-CNN: Swap order of convolutions and region extraction
- Faster R-CNN: Compute region proposals within the network
- Deeper networks do better
'컴퓨터비전' 카테고리의 다른 글
| [CS231n 2016] 10강 Recurrent Neural Networks (0) | 2022.07.18 |
|---|---|
| [CS231n 2016] 9강 Understanding and Visualizing Convolutional Neural Networks (0) | 2022.07.15 |
| [CS231n 2016] 7강 Convolutional Neural Network (0) | 2022.07.11 |
| [CS231n 2016] 6강 Training NN part 2 (0) | 2022.07.05 |
| [CS231n 2016] 5강 Training NN part 1 (0) | 2022.07.04 |