
Recurrent Neural Network

one to one : 일반적인 Neural Networks으로 고정된 사이즈의 input이 들어간다.(ex 이미지..) output에서도 마찬가지로 고정된 사이즈의 score를 반환한다.
one to many : 이미지를 input으로 받아 이미지를 설명하는 단어들의 sequence를 반환한다.
image -> sequence of words
e.g. Image Captioning
many to one : 단어들로 구성된 sequence를 통해 하나의 class로 반환한다.
sequence of words -> sentiment
e.g.Sentiment Classification
many to many : 한국어 문장을 영어 문장으로 번역
seq of words -> seq of words
e.g. Machine Translation, Video classification on frame level
모든 각각의 time step에 대한 예측은 현재의 프레임 + 지나간 프레임에 대한 함수로 이루어지게 된다.
Sequential Processing of fixed inputs
고정된 input을 sequential하게 처리한 경우

Sequential Processing of fixed outputs
고정된 사이즈의 output을 sequential하게 처리한 경우

=> one to one에 경우에도 recurrent neural net을 사용할 수 있다.

RNN에서는 연속적인 input을 받아 특정 time step에서의 vector를 예측하게 된다.
따라서 위와 같은 recurrence function을 이용한다. -> sequence를 처리할 수 있게 된다.
단, 매 time step 마다 동일한 함수, 파라미터 set을 사용해야 한다.
Vanilla Recurrent Neural Network

ex) Character-level language model example
input을 one-hot encoding, W_xh : x에서 h로, W_hh : h에서 h로, W_hy : h에서 y로


각각의 time step에는 softmax classifier가 존재해 loss를 구할 수 있다.
W_xh, W_hh, W_hy는 모든 time step에서 동일하다.
코드 : https://gist.github.com/karpathy/d4dee566867f8291f086
Minimal character-level language model with a Vanilla Recurrent Neural Network, in Python/numpy
Minimal character-level language model with a Vanilla Recurrent Neural Network, in Python/numpy - min-char-rnn.py
gist.github.com
결과

Searching for interpretable cells
각 cell에서 activate되는 부분이 존재하는 것을 확인 가능
quote(따옴표) detection cell, line length tracking cell, ...


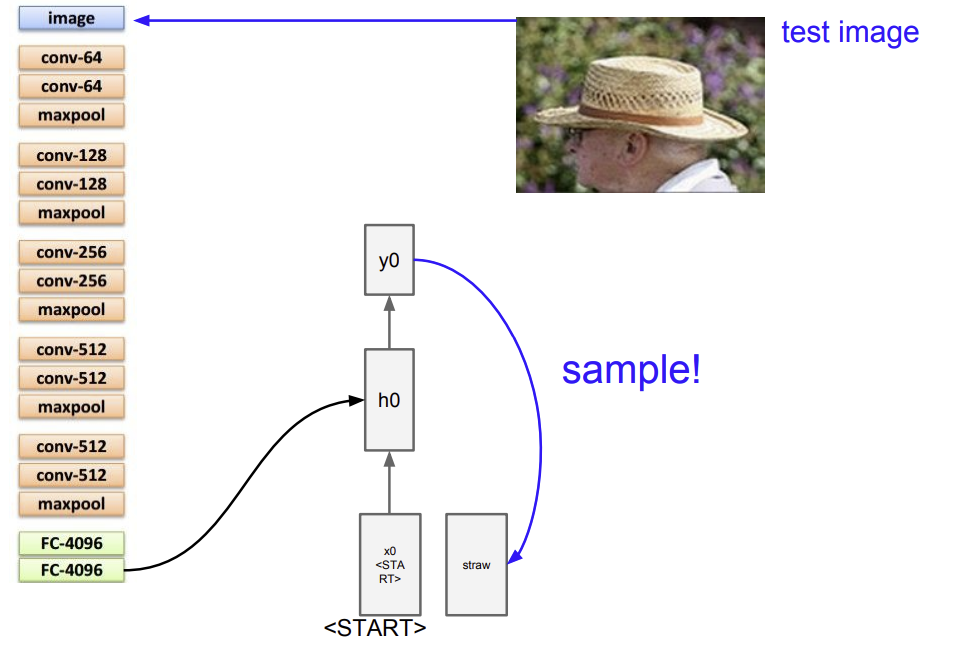
Image Captioning
CNN과 RNN 2개의 모듈로 이루어져 있음.
CNN -> 이미지 처리
RNN -> sequence 처리
=> 두 개의 모듈은 마치 1개의 모델처럼 back propagation이 진행됨(end to end)
이미지 정보를 기억하는 일, 다음 단어를 예측하는 일 모두 수행해야 함.

Image captioning의 과정


기존의 RNN에서 W_ih(image to hidden)를 추가해준다.


ex) microsoft coco

RNN의 미래..
-> attention, 이미지의 부분을 보고 그 부분에 적합한 단어를 추출할 수 있음. 후에 어디 부분을 봐야하는 지도 예측

LSTM
RNN에 문제가 있어 보통 LSTM을 사용함.
LSTM에는 hidden state와 함께 cell state가 존재한다는 것이 차이점.





RNN vs LSTM

RNN => transformative, LSTM => additive(+)
또한 RNN은 vanishing gradient 문제가 존재, LSTM 은 +가 있기 때문에 이는 distributer의 역할을 해 gradient를 그냥 전달할 수 있음.

Recall : "PlainNets" vs "ResNets"

GRU... 같은 것도 존재
Summary
- RNNs allow a lot of flexibility in architecture design
- Vanilla RNNs are simple but don’t work very well
- Common to use LSTM or GRU: their additive interactions improve gradient flow
- Backward flow of gradients in RNN can explode or vanish. Exploding is controlled with gradient clipping. Vanishing is controlled with additive interactions (LSTM)
- Better/simpler architectures are a hot topic of current research
- Better understanding (both theoretical and empirical) is needed.
'컴퓨터비전' 카테고리의 다른 글
| [CS231n 2016] 13강 Segmentation and Attention (0) | 2022.07.26 |
|---|---|
| [CS231n 2016] 11강 CNNs in Practice (0) | 2022.07.21 |
| [CS231n 2016] 9강 Understanding and Visualizing Convolutional Neural Networks (0) | 2022.07.15 |
| [CS231n 2016] 8강 Spatial Localization and Detection (0) | 2022.07.14 |
| [CS231n 2016] 7강 Convolutional Neural Network (0) | 2022.07.11 |