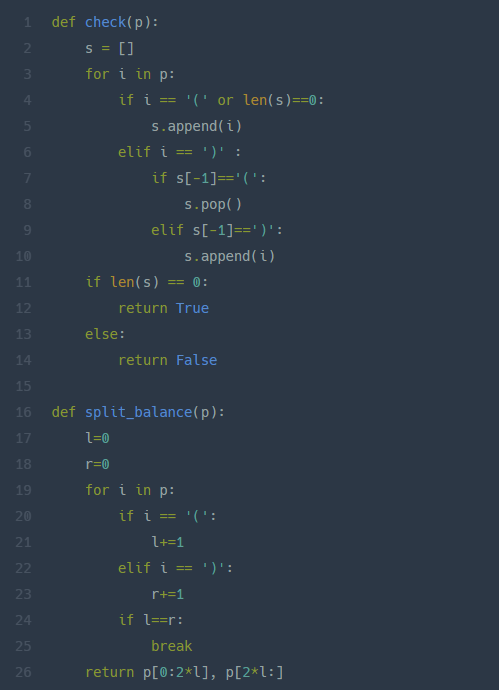
- Image Classificaiton
Image Classification은 컴퓨터 비전의 핵심 task이다. 이는 이미지를 input으로 하여 lable의 집합에서 어떤 하나의 레이블을 반환해준다. 이것이 가능하다면 Detection, Segmentation, Image captioning이 수월하게 가능해진다.
- The problem : Semantic gap
이미지는 [0,255] 사이의 숫자들로 이루어진 3D array로 표현되어진다.
e.g 300(height)X100(width)X3(channel)
- The problem
Viewpoint Variation : 보는 시각(카메라 위치)에 따라 이미지가 달리 보일 수 있다.
Illumination : 조명에 따라 이미지가 달리 보일 수 있다.
Deformation : 형태의 변형으로 이미지가 달리 보일 수 있다.
Occlusion : 다른 사물로 분별하고자 하는 물체가 가려져(은폐, 은닉) 식별이 어려울 수 있다.
Background clutter : 배경과 구분이 안 되는 수준으로 비슷하여 식별이 어려울 수 있다.
Intraclass variation : 같은 클래스 내에서 구분
- An image classifier
이미지(input) -> 레이블(output)
숫자 정렬과 같은 다른 알고리즘과는 달리, 특정 클래스를 구분해내는 hard-code 알고리즘을 구하는 명확한 방법은 존재 X
역사적으로, 그렇게 하고자 하는 시도들은 있어왔다... 이미지를 보고 특징적인 edge, shape로 라이브러리화를 하고 방향과 같은 특징들을 비교,, 그것으로 classifiy,, 하지만 scalable 하지 않아 잘 사용 X..
=> 그래서!.. Data-driven approach가 등장함.
- Data-driven approach
train : 훈련 이미지, 훈련 레이블 -> 모델
predict : 모델, 테스트 이미지 -> 테스트 레이블
1. 이미지, label 데이터셋을 수집
2. 머신러닝을 이용해 이미지 분류기를 훈련
3. 테스트 이미지들로 이미지 분류기를 평가
- First classifier : Nearset Neighbor Classifier
(현재는 사용하지 않는 분류기..)
train : 모든 훈련 이미지와 레이블을 그저 기억함.
predict : 테스트 이미지를 모든 훈련 이미지와 하나하나 비교하여 훈련 이미지와 가장 비슷한 레이블로 예측
Dataset : CIFAR-10
10개 레이블, 32X32 50,000개의 훈련 이미지, 10,000개의 테스트 이미지

Nearest Neighbor Classifier는 distance metric을 이용해 이미지를 비교하게 된다.

코드로 표현하면 다음과 같이 된다. numpy의 브로드캐스트 기능을 사용해 간단하게 표현 가능하다.

해당 classification의 시간은 training data의 크기가 늘어남에 따라 linear 하게 증가한다.
test time의 속도는 절대적으로 중요한 요소이기 때문에 Nearest Neighbor classification은 이와 같은 맥락으로 부적절하다.
반대로, CNN은 훈련에서 많은 시간을 필요로 하지만 test과정에서는 상대적으로 매우 짧은 시간을 필요로 한다.
Nearset Neighbor Classification에서는 거리의 종류 또한 hyperparameter이다.
L1 distance, L2 distance..
- Classifier : K-Nearest Neighbor
K개의 가까운 이미지들을 찾아, 이 이미지들의 다수결로 vote 해 레이블을 찾아내는 방법

Q Nearest Neighbor Classifier로 훈련 데이터를 예측했을 때의 정확도는?
100%, 이미 훈련했던 이미지로 테스트를 진행하는 것이기 때문에 100%가 나온다.
Q K-Nearest Neighbor로 훈련데이터를 예측 했을 때의 정확도는?
상황에 따라 다름.. 다수결로 인해 부정확한 결과가 나올 수도 있다.
어떤 distance, 어떤 K로 설정해야 할까?... -> hyperparameter를 어떻게 설정해야 할까?
=> 문제에 따라 다르기 때문에, 주어진 환경에서 parameter를 실험해보고 가장 좋은 성능을 내는 parameter를 선택해야 함. 따라서 이 과정에서 Validation data를 사용해 hyperparameter를 튜닝하는 과정이 필요하다. (test data를 튜닝하는 과정에서 사용하면 안 됨)

데이터 수가 적은 경우에는 사이클을 돌면서 한 fold가 validation data가 되는 Cross-Validation이라는 방법을 사용해도 된다. 결괏값은 평균 결괏값을 사용하면 된다.
- K-Nearest Neighbor는 현실에서 사용하지 않는다.
1. test time이 너무 오래 걸려 사용하는 것에 제약이 크다.
2. distance가 현실적으로 정확한 예측을 할 수 없다. (동일한 distance를 가지면 같은 이미지임을 내포하고 있기 때문)
-> shifted image, messed up image, darkened image
- Linear Classification
파라미터 기반의 접근 방식을 취하고 있다. Nearest 방식은 non-parametric approach


그래서 Linear Classifier는?
- Just a weighted sum of all the pixel values in the image
- counting colors at different spatial position

-> capacitiy에 한계가 있음.

Q linear classifier가 구분하기 힘든 종류의 데이터셋은 무엇이 있을까?
색상 반전 이미지, 흑백 이미지, 형태는 같지만 색상이 다른 경우..
반대로 위치가 다른 경우는 쉽게 구분이 가능할 것임.
따라서 지금까지 f(x_i, W, b) = Wx_i + b는 이미지를 score로 바꿔주는 일종의 (linear) score function이라고 볼 수 있다.
앞으로 할 것은 이 score를 조정해주는 loss function을 정의해야 한다.
'컴퓨터비전' 카테고리의 다른 글
| [CS231n 2016] 7강 Convolutional Neural Network (0) | 2022.07.11 |
|---|---|
| [CS231n 2016] 6강 Training NN part 2 (0) | 2022.07.05 |
| [CS231n 2016] 5강 Training NN part 1 (0) | 2022.07.04 |
| [CS231n 2016] 4강 Backpropagation and NN part 1 (0) | 2022.07.01 |
| [CS231n 2016] 3강 Loss fn, optimization (0) | 2022.06.30 |